Desafio: Acesso económico à habitação no Concelho de Lisboa
Modelação de Clusters e Políticas Públicas de Habitação: O Caso da Plataforma Habitar Lisboa | Cluster Modeling and Public Housing Policies: The Case of the Habitar Lisboa Platform
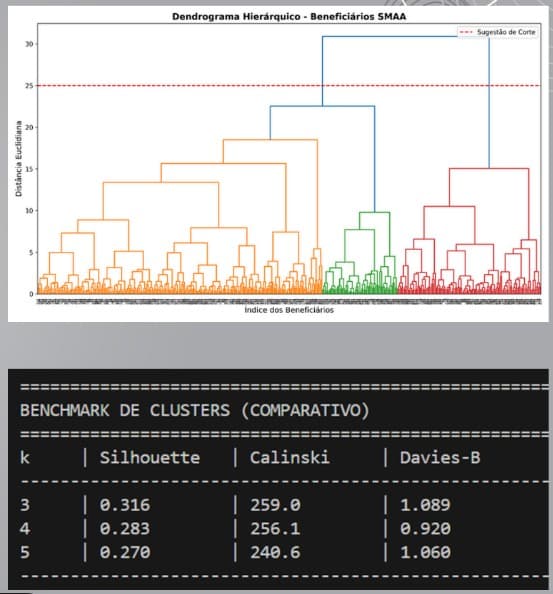
A Área Metropolitana de Lisboa enfrenta uma disparidade crescente entre os rendimentos familiares e os custos de habitação, exigindo políticas públicas baseadas em evidência. Este estudo analisa dados de 2023/2024 da plataforma “Habitar Lisboa”, abrangendo o Programa de Arrendamento Apoiado (PAA), o Programa de Renda Acessível (PRA) e o Subsídio Municipal ao Arrendamento Acessível (SMAA). A metodologia seguiu o framework CRISP DM (Cross Industry Standard Process for Data Mining). Na fase de modelação, comparou se o desempenho do algoritmo K Means com o Clustering Hierárquico. Os resultados demonstraram que o Clustering Hierárquico é superior para a dimensão dos datasets analisados, oferecendo maior estabilidade e robustez face a outliers.
A segmentação permitiu identificar perfis sociológicos críticos invisíveis em métricas tradicionais, nomeadamente: agregados em “insolvência técnica” com despesas superiores aos rendimentos (SMAA), famílias numerosas em risco de sobrelotação (PAA) e jovens qualificados impedidos de se emancipar (PRA). O estudo conclui com simulações de impacto orçamental, demonstrando que a priorização de apoio baseada nestes clusters de vulnerabilidade maximiza a eficiência social dos fundos municipais em comparação com critérios puramente demográficos.
Lisbon Metropolitan Area faces a growing disparity between household incomes and housing costs, requiring evidence-based public policies. This study analyzes 2023/2024 data from the “Habitar Lisboa” platform, covering the Supported Rental Program (PAA), the Affordable Rent Program (PRA), and the Municipal Subsidy for Affordable Rent (SMAA). The methodology followed the CRISP DM (Cross Industry Standard Process for Data Mining) framework. During the modeling phase, the performance of the K-Means algorithm was compared with Hierarchical Clustering. The results demonstrated that Hierarchical Clustering is superior for the size of the analyzed datasets, offering greater stability and robustness in the face of outliers.
The segmentation identified critical sociological profiles not visible in traditional metrics, namely: households in “technical insolvency” with expenses exceeding income (SMAA), large families at risk of overcrowding (PAA), and qualified young people prevented from becoming independent (PRA). The study concludes with budget impact simulations, demonstrating that prioritizing support based on these vulnerability clusters maximizes the social efficiency of municipal funds compared to purely demographic criteria.
Autores: João Santos e Ana Cardoso | Professor Responsável: Leonor Melo, ISEC